音声ファイルから文字起こしをする
録音済みの音声ファイルをアップロードして文字起こしを行う方法をご紹介します。会議の録音、インタビュー、講演など、様々な音声コンテンツを簡単に文字化できます。
重要: 音声ファイルアップロード機能は Windows 環境でのみご利用いただけます。iPhone では現在サポートされていません。
音声ファイルのアップロード
1. アップロード画面を開く
メニューの「ファイルアップロード」を押します。
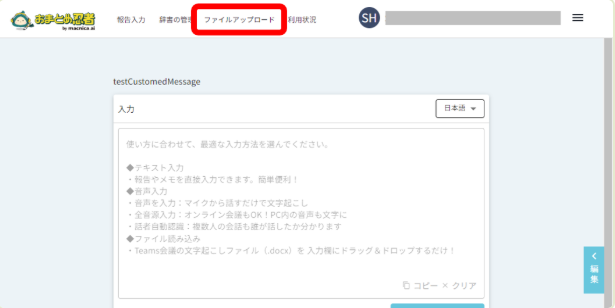
2. ファイルを選択
音声ファイルをドラッグ&ドロップするか、「ファイル選択」ボタンから音声ファイルを選択します。
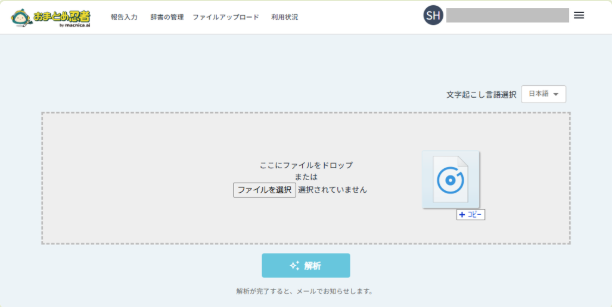
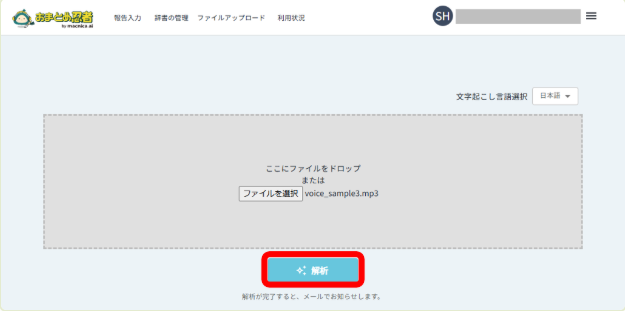
3. 解析を開始
「解析」ボタンを押して、文字起こし処理を開始します。
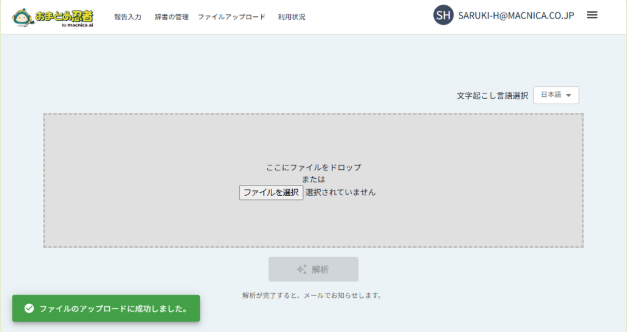
4. アップロード完了を確認
音声ファイルのアップロード中はこの画面から離れないようにしてください。正常にアップロードできないことがあります。
「ファイルのアップロードに成功しました」の通知が表示されたら、アップロードは完了です。
5. 処理完了の待機
アップロード後、サーバー側で音声の解析処理が行われます。ファイルのサイズによって処理時間は異なります。処理が完了すると、登録しているメールアドレスに通知が届きます。
文字起こし結果の確認
1. 通知メールの確認
文字起こしが完了すると、以下のいずれかのメールが届きます。
- 成功時: 「おまとめ忍者 音声ファイル解析完了通知」
- 失敗時: 「おまとめ忍者 音声ファイル解析失敗通知」
2. 文字起こし結果にアクセス
成功通知メールに記載されている URL をブラウザで開きます。
3. 文字起こし結果の確認
URL を開くと、「報告内容の入力」に文字起こし結果が出力されています。この内容を利用して、通常の音声入力と同様におまとめ機能を使用できます。
音声ファイルアップロード機能の特徴
対応ファイル形式
- 現在、ファイルの拡張子は「.mp3」と「.wav」に対応しています。
ファイルサイズ制限
- 1 度にアップロードするファイルサイズは 2GB までとしてください。
- 話者認識を有効にしている場合、音声ファイルの最大の長さは3時間になります。
処理時間の目安
- 処理時間はファイルサイズによって異なります。
- 目安: 2 時間分の音声ファイル → 約 40 分
結果の保存期間
- 文字起こしデータは、通知メールから 7 日間ダウンロードできます。
- 重要なデータは必ずダウンロードして保存してください。
話者認識機能との連携
音声ファイルアップロード機能は「話者認識」機能にも対応しています。複数の発言者が含まれる音声ファイルの場合、誰が発言しているかを自動的に判別し、各発言に発言者ラベルを付けることができます。
辞書機能との連携
音声入力での文字起こしと同様に、以下の辞書機能が利用可能です:
- プライベート辞書
- パブリック辞書
- 文字起こし言語設定
詳しい使い方は「プライベート辞書とパブリック辞書」をご参照ください。
よくある質問
Q: アップロードしたファイルが「解析失敗」となった場合はどうすればよいですか?
A: 以下の点を確認してください:
- ファイル形式が対応形式(.mp3 または.wav)であるか
- ファイルサイズが制限(2GB)以内であるか
- ファイルが破損していないか
問題が解決しない場合は、別の形式に変換するか、ファイルを分割してアップロードしてみてください。
Q: 文字起こし結果の精度を上げるコツはありますか?
A: 以下の点に注意すると精度が向上します:
- クリアな音声品質のファイルを使用する
- バックグラウンドノイズが少ない録音を使用する
- 業界特有の用語や固有名詞は辞書に登録する